【大唐杯】人工智能与机器学习-集成学习/决策树

集成学习
聚合一组预测其的预测,得到的结果比单个预测器要好,这样的一组预测器称为集成,这种技术称为集成学习。
分为四类:
voting 投票
bagging 包装
boosting 提升
stacking 堆叠
集成学习-voting
相同数据集,不同分类器,根据最终大多数出现的结果作为预测结果。



bagging 自举汇聚法
在不同的训练集随机子集上进行训练,分类器相同。
采样时样本放回叫做bagging,采样时不放回叫pasting

- 随机森林
- 对每个样本随机有放回的从训练集中抽取(bootstrap sample方法)
![]()

boosting 提升法
将几个弱学习器合成一个强学习器的集成方法,提升法的总体思路大多是循环训练预测其,每一次都对其前序做一些改正。


决策树
决策树是什么,如何构造?
-
熵:表示随机变量的不确定性
熵越大,随机变量的不确定性越大!![]()
C_k是结果的类别,D整个数据集的条数
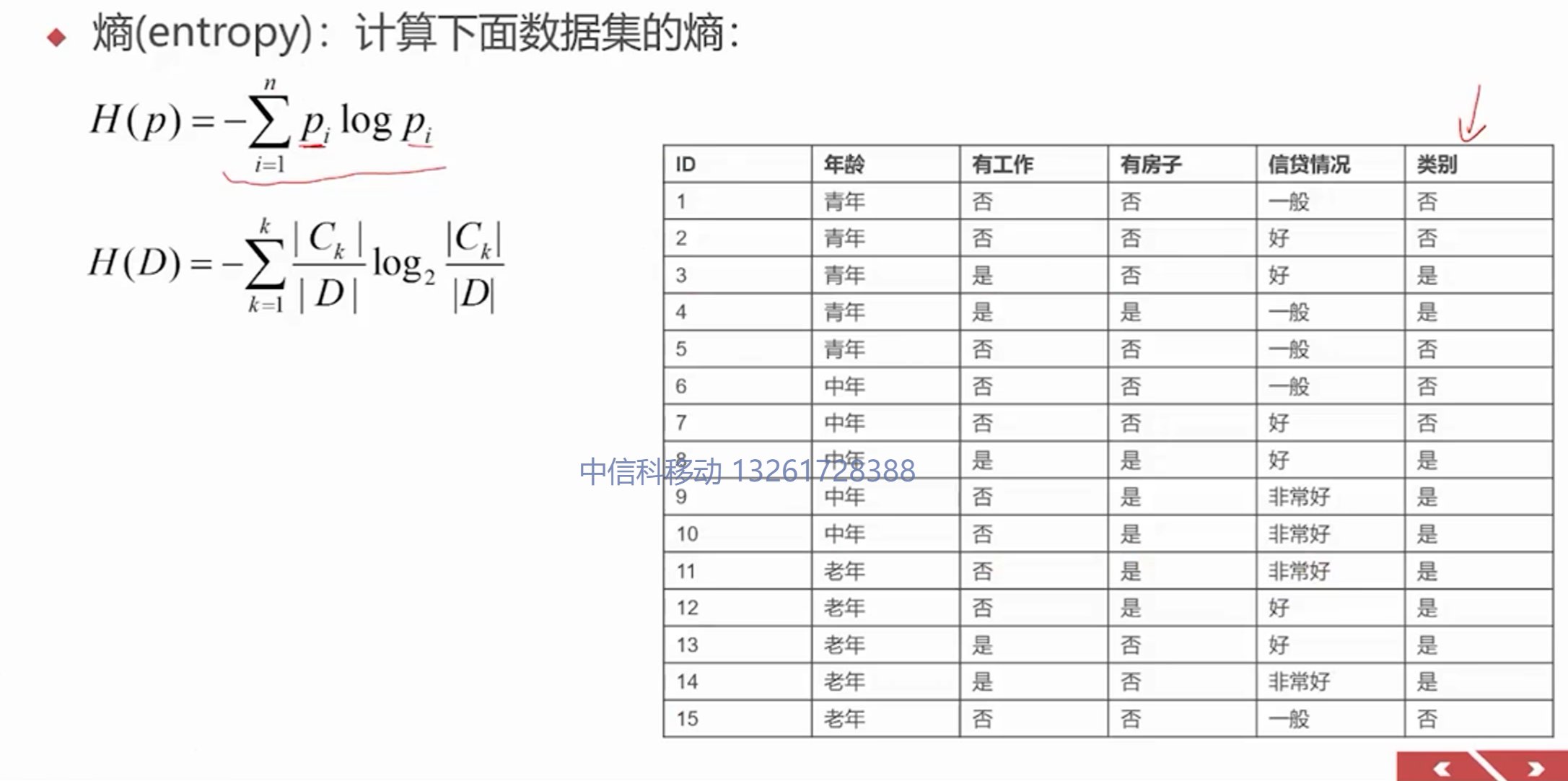
-
条件熵
![]()
按条件分类后,分别计算各类别的熵,按类别加权计算平均。之后根据信息增益准测选择最优特征。 -
信息增益
信息增益(也叫互信息 mutual information)
增益越大,条件熵越小,增益越强,选增益大的作为划分属性 -
计算过程
![]()
-
几种决策树算法
- ID3 Iterative Dichotomiser 3(迭代二叉树三代)
- 对各个节点递归地计算信息增益
- C4.5 对ID3的改进
- 使用信息增益比来选择特征
![]()
- CART 生成的是二叉树
![]()
- 基尼指数与熵类似
- ID3 Iterative Dichotomiser 3(迭代二叉树三代)




评论
评论插件加载失败
正在加载评论插件